Záznam ze Vzdělávacího okénka HAVIT z 3. dubna 2024, kde Daniel Hrubý povídal o passwordless přihlašování.
Passwordless přihlašování Windows Hello for Business [Dan Hrubý, HAVIT Vzdělávací okénko, 3.4.2024]
Zanechat odpověď
Záznam ze Vzdělávacího okénka HAVIT z 3. dubna 2024, kde Daniel Hrubý povídal o passwordless přihlašování.
Ještě než se rozpoutala kauza Benešovské nemocnice, dostalo se návštěvy ransomware i nám v HAVITu. Klasický následek – zakryptování souborů na discích za účelem získání výkupného. Poslední dobou se to docela mele, za poslední tři měsíce víme o nejméně dvou dalších případech v našem bezprostředním okolí (naši zákazníci), dalšími případy se to po internetu hemží.
Vesměs mají tyto případy jedno společné – nikde se nedočtete, jak konkrétně se ke komu škodlivý software dostal. Vše bývá zahaleno do obecné mlhy a spekulací typu „závadné přílohy mailů“ či „nezabezpečený systém“. Proto jsem se rozhodl veřejně sdílet, co víme o našem vlastním případu, jaké byly následky a jaké plyne pro nás poučení. Věřím, že to může mnohé inspirovat k vylepšení vlastního uspořádání.
V úterý 26. listopadu ráno jsem přišel do práce zhruba stejně s kolegou, který po usednutí a pár kliknutích zahlásil cosi ve smyslu „Sakra, já mám zašifrovanej počítač.“ Skok po síťovém kabelu už bohužel nic nezachránil – jak se během následujících chvil ukázalo, zašifrovaný byl nejenom počítač jeho, ale taky všechny on-premise servery v naší firemní síti.
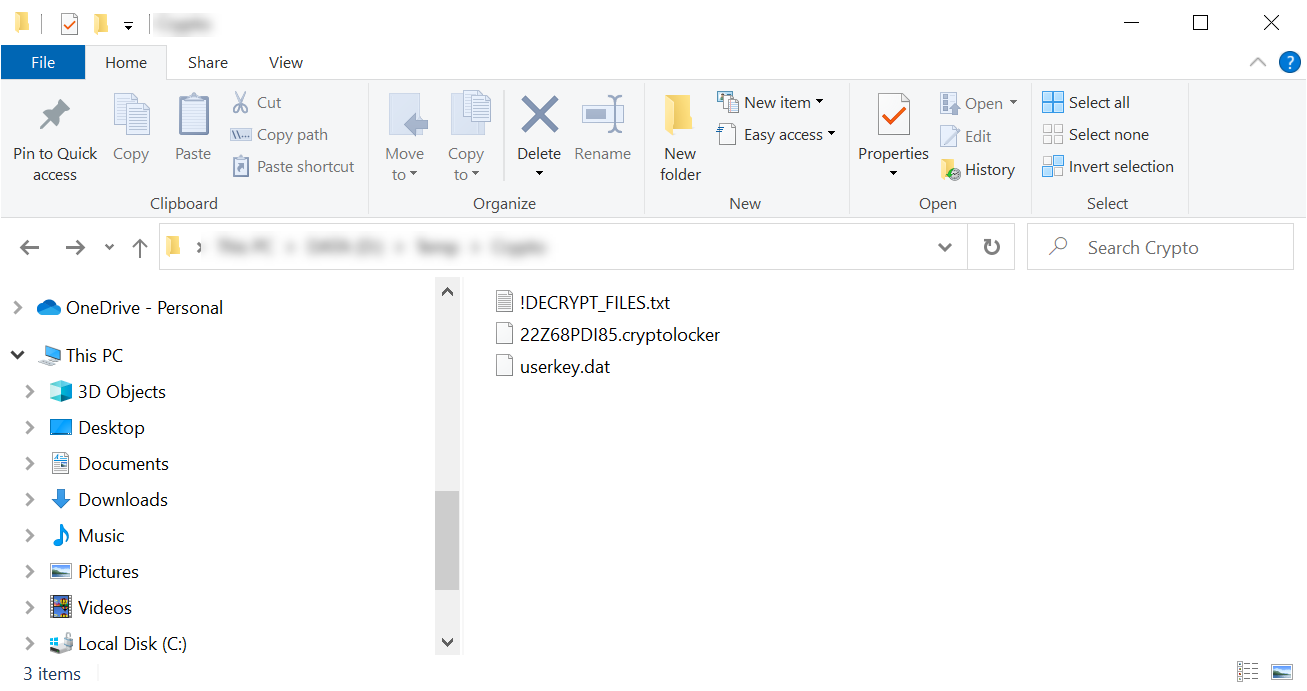
> Welcome. Please read this important instruction. Cant you find the necessary files? Is the content of your files not readable? Congratulations, you files have been encrypted. > Whats happened? Your documents, photos, databases and other important files have been encrypted with strongest encryption and unique key, generated for this computer Decrypting of your files is only possible with the private key and decrypt program The only copy of the private key, which will allow you to decrypt your files, is located on a secret server > To receive your private key follow instruction: 1) Write to our email: recovery.company@protonmail.com or rapid.file@tuta.io 2) Tell us your personal ID: KR5FLA6R1OPEI4
Zašifrovány nakonec byly:
Od prvního okamžiku bylo jasné, že cestou zaplacení výkupného jít nechceme. Vytrhali jsme všechny kabely ze switchů, vypnuli WiFi, stáhli bootovací USB pro základní kontrolu a začali obcházet jednotlivé počítače i servery.

Zkontrolované počítače jsme zapojovali zpět do čisté sítě, přísně oddělenou samostatnou síť jsme si vytvořili i pro práci se špinavými servery (tu jsme nakonec ani moc nevyužili, nebylo co zachraňovat).
Důležitější pro nás bylo, co zůstalo nedotčeno – kromě těch pár desítek vývojářských workstation to byla zejména naše kompletní cloudová infrastruktura:
Díky tomu jsme byli nakonec ochromeni jen relativně krátce a v zásadě nijak kriticky.
Po pár hodinách počátečního chaosu a zjišťování rozsahu bylo zřejmé, že jediný možný recovery plán je kompletní rebuild celé on-premise infrastruktury od nuly, protože
…z on-premise nezbylo opravdu nic, přišli jsme i o AD doménu bez náhrady. Naše zálohovací strategie byla primárně zaměřena na události spíše více pravděpodobné – selhání jednotlivých kusů hardware, náhodné izolované ztráty dat, atp. Co se stalo, svým rozsahem spíše připomínalo živelní katastrofu s jediným rozdílem – zbylo nám holé železo, na které jsme mohli začít stavět znovu.
Proběhla rychlá strategická porada o prioritách, o podobě nové infrastruktury, o rozdělení úkolů a pustili jsme se do toho:
V zásadě nám trvalo postupně zhruba týden než jsme se dostali na víceméně plnou původní funkčnost, pár detailů ladíme dodnes (např. změna VPN z Microsoft RRAS na IKEv2 přímo přes router, atp.)
I přesto, že jsme měli a máme nejdůležitější služby v cloudu, byli jsme první dva dny dost zásadně paralyzovaní (první den jsme odhadem jeli na 5% výkonu a řešili jen kritické požadavky zákazníků, druhý den možná na 30%, pak už se to nějak rozběhlo).
Přestože jsme měli od drtivé většiny věcí datové zálohy a přišli jsme v podstatě jen o opomenutý starý help-desk, jednalo se svým rozsahem o událost, která byla pro nás zcela mimořádná a srovnatelná s živelní katastrofou. V zásadě se ukázalo, jak obrovskou výhodou pro nás je strategie postupného cloudovatění našeho fungování. O kolik hůře bychom na tom byli, kdybychom zároveň přišli o kdysi u nás běžící Exchange a TFS, to si raději ani nepředstavuji.
No a jak se to k nám dostalo? Jistotu nemáme, protože jsme v tom zmatku napadený počítač smazali a na hlubší analýzu nedošlo. Myslíme si nicméně, že příčinou byla kombinace chybějících aktualizací Windows (kolega měl plný systémový disk a aktualizace se mu tak neinstalovaly) a publikovaného rozhraní RDP na veřejnou IP adresu (přímý port mapping na routeru).
Smůlou pak už bylo, že zrovna kolega zároveň občas pracuje se servery jako Domain Admin (intranet RDP), byť jinak pracuje pod neadministrátorským účtem.
Jiné běžné příčiny jsme vyloučili – žádný závadný soubor neotevřel, žádný nakažený soubor se nikde nenašel, uživatelské účty měly unikátní a netriviální hesla.
…neštěstí nechodí nikdy samo. :-)
Viselo to tak nějak ve vzduchu, po internetu se množily zprávy, kdo zrovna podlehl ransomware, už jsme věděli, že nikdo není neprůstřelný, jistota o způsobu první nákazy nebyla.
Jeden krásný podvečer 5.12. mi volá kolega: „Je to tu zas! XY má zakryptovaný počítač.“ (jiný kolega).
Cvičení se opakuje. Sprint k síťovému kabelu nakaženého PC, odpojení všech od sítě, kontrola všech strojů antivirem z bootovacího USB.

Zkrátím to – zašifrovaný byl jediný počítač (jiným ransomware, byť taky šifrující) a příčina se ukázala celkem rychle. V zápalu boje, jak jsme přišli o VPN a trvá nám připravit novou, tak jsme podlehli potřebám pár dalších kolegů a namapovali jsme jim pro vzdálený přístup RDP přímo na veřejnou IP adresu. Bylo otázkou hodin, nikoliv dnů, než došlo k průstřelu skrze zapomenutý lokální účet jednoho z nich – admin s heslem admin.
K žádnému rozšíření na další počítače nedošlo, stačilo přeinstalovat jedno PC.
V podstatě jsem za tento druhý případ rád, protože poměrně levně pomohl zviditelnit velmi slabé místo naší ochrany – RDP, resp. obecně chybu cokoliv vypublikovat do veřejné sítě, co není „pod kontrolou“.
Kdo mě zná, ví, že nejsem příznivce antivirů. Sám mám na svém počítači zakázaný i Windows Defender a opírám se v této oblasti o tři jiné pilíře:
Na první dva nelze plně spoléhat, klíčový pro přežití je zejména ten třetí – zálohování.
V našem případě se potvrdilo, že antivirus by zřejmě nic nevyřešil. První kolega měl aktivní Defender (byť možná se starší databází), ale z event-logu bylo vidět, jak si s ním ransomware obratně poradil a shodil ho (stejně obratně sundal i běžící VMs z HyperV hostů a zašifroval VHDX soubory).
A zálohování? Zachránilo nás, byť o trochu kostrbatěji než bych si ideálně představoval. Pár věcí uniklo naší pozornosti při definování zálohovacích scénářů a způsob obnovy byl díky zániku řídícího DPM zdlouhavý.
Skončili jsme naštěstí ve stavu, kdy jsme měli dvě použitelné zálohy:
Neměli jsme zálohu on-prem Active Directory. Mou strategií je eliminace/minimalizace závislosti na on-prem AD, nicméně nové AD vzniklo a zálohujeme ho nyní jako „celý VM“.
Pro zkrácení doby zotavení jsme přidali nejenom zálohování celých VHDX, ale pro některé klíčové servery zálohujeme i do Azure v režimu Recovery Services (tj. celý VM k rychlému rozjetí přímo z Azure). Obecně však prostě cloudovatíme a on-prem servery držíme jen pracovní s režimem „dvě HyperV repliky + v případě ztráty reinstall“ (no a holt když se to sejde všechno najednou, tak ten rebuild trvá).
Čerstvě jsme přidali další nezávislé zálohování na Synology NAS. Bude to taková naše off-site černá skříňka s konektivitou pouze „zevnitř ven“, u mě doma na fyzicky odděleném segmentu sítě.
(Přestavěl jsem nedávno domácí síť na Ubiquity UniFi a musím říct, že co je Ubiquity na síťařinu, to je Synology v NAS. Jsou to fakt pěkné ekosystémy.)
Cenné školení bojem se nám dostalo i v oblasti ochrany. Celá firma jsme v podstatě IT profesionálové, příčetného uživatelského chování, ale pořád jen lidi – chybující.
Pár věcí, které jsme po popsaných událostech změnili:
…no a samozřejmě vycházíme z toho všeho posilněni. Vyzkoušeli jsme si disaster recovery, objevili slabá místa, dostali přes prsty, získali nové zkušenosti.
Nasazuji aplikace pomocí WDP na server (Windows Server 2008). Pokud msdeploy.exe předám v argumentech authType=basic a dále username a password, které používám pro přihlášení, vše funguje. Tím mám ověřeno, že můj účet má oprávnění, existuje website, atp. Nechci však psát své heslo a rád bych využil integrovaného zabezpečení.
Proto z příkazové řádky vynechávám username i password a nastavuji authType=ntlm. Pokus o nasazení aplikace se nedaří, jsem odmítnut (unauthorized).
Po drobném bádání dohledávám, že Windows autentizace je pro službu wmsvc standardně vypnutá a musí se zapnout v registrech: Pod HKEY_LOCAL_MACHINE\Software\Microsoft\WebManagement\Server je potřeba vložit DWORD klíč WindowsAuthenticationEnabled s hodnotou 1. A restartovat službu wmsvc.
Poté je již možné se k serveru připojit s využitím NTLM.
Na Terminal Services lze nastavit, aby se odpojené (disconnected) session automaticky ukončily:

Pozor, že se jedná opravdu o tvrdé nevybírané ukončení session, takže se to nebude mazat s žádnou neuloženou rozpracovanou úlohou, běžícím Profilerem/Debuggerem/Fiddlerem nebo čímkoliv podobným.
Dneska ráno nás v práci uvítal critical ticket v HelpDesku, jednomu ze zákazníků „nešel web a všechno, co po přihlášení zkusil, vedlo na homepage“. Hned se nám spojilo, že to je web, na který kolega nastavoval přesměrování HTTP requestů na HTTPS a zkoušel si různé způsoby, jak to udělat.
Jeden z testů, které udělal, byl přes <httpRedirect> (HTTP Redirection). Pak od něj ale upustil a redirect nastavený přes IIS Manager zase vypnul.

Souhra okolností chtěla, aby toto zapnutí a vypnutí způsobilo poměrně velký problém.
Po IIS Manageru zůstalo v hlavním ~/web.configu webu toto:
<system.webServer> <httpRedirect enabled="false" destination="https://chester.xerox.cz" httpResponseStatus="Permanent" /> </system.webServer>
To by samo o sobě nevadilo. Peklo však nastalo v okamžiku, kdy se to potkalo s web.config soubory v podsložkách, v nichž byla různá specifická přesměrování od vývojářů:
<system.webServer> <httpRedirect enabled="true" exactDestination="true"> <add wildcard="/Old-URL.aspx" destination="New-URL.aspx"/> ... </httpRedirect> </system.webServer>
Když se to celé sečetlo, tak ve všech takových podsložkách se reaktivoval disablovaný redirect z rootového web.configu a veškeré requesty na resources v dané složce přesměrovával.
…další důvod proč nemám rád, když IIS Manager modifikuje web.config. Hlavním je ten, že při nasazování chci web.config přepisovat vždy celý novou verzí a jakékoliv production-specific volby z něj mít vyextrahovány třeba pomocí atributu configSource.
Pokud přepneme application pool do Classic managed pipeline mode a dostáváme podivnou chybu 404, jedná se velmi pravděpodobně o chybu
HTTP Error 404.2 - Not Found The page you are requesting cannot be served because of the ISAPI and CGI Restriction list settings on the Web server. Error Code 0x800704ec
Tuto podrobnější chybu se můžeme dozvědět, pokud přístup uděláme přímo ze browseru běžícím na serveru (což bohužel ne vždy lze, viz třeba problémy s lokální integrovanou authentizací).
Každopádně problém je v tom, že nejsou v nastavení IIS povoleny ISAPI extenze pro ASP.NET 4.0.
Pozor na Task Scheduler, pokud mu nastavujete limit „Stop task if it runs longer than“. Ten limit je tam totiž dvakrát, a už jsem se několikrát napálil, že na jednom místě byl nastaven dostatečný a z druhého místa mi to task sestřelovalo a nedobíhal:
Na IIS6 existoval ve složce System32\ jednoduchý skript k vypsání seznamu worker-procesů a jejich příslušnosti k jednotlivým application poolům IIS:
iisapp.vbs
Na IIS7 už tento skript není, ekvivaltentní příkaz z System32\inetsrv\ však je
appcmd list wp

V nastavení application poolu na IIS je zastrčeno jedno nastavení s výchozí hodnotou 1, které je poměrně zrádné, pokud ho někdo změní a neví, co to přesně znamená.
Jde o volbu „Maximum Worker Processes“ a neznalé svádí tuto hodnotu z jedničky zvětšit na vyšší číslo.
Co to však ve skutečnosti znamená – jde o to, že IIS pustí pro Application Pool více instancí Worker Processu (w3wp.exe), které jsou navzájem izolované. Vznikne tak více nezávislých instancí aplikací běžících na daném Application Poolu a celé se to začne chovat jako Web Garden (= lokální virtuální Web Farm na jednom serveru). Následky jsou pak prakticky stejné, jako běh aplikace na webové famě – instance aplikace mezi sebou nezdílí kontext (Application, Cache, in-proc Session, atp.).
Protože každý Váš request pak může vyřdit jiná instance aplikace, projevy mohou být např. následující:
Osobně v běžném provozu nenacházím scénář, kde by Maximum Worker Processes mělo být nastaveno jinak než na 1. Dokážu si představit jedině, že někdo chce záměrně testovat chování své aplikace na webové farmě, nebo nějaké obskurní důvody s unmanaged componentami, nebo řešením nedostatečné thread-safety aplikace.
Pokud jste u RDP clienta byli zvyklí na přepínač /console, pak vězte, že ho Microsoft přejmenoval na přepínač /admin:
mstsc.exe /admin
Cílovou adresu je možné předat přepínačem /v
mstsc.exe /v:my.server.com
Je to zjednodušeně řečeno připojení na jednu vyhrazenou session RDP (přesněji řečeno lokální konzoli, jako u běžného Remote Desktopu), kde se zejména neuplatňuje limit 3 admin-session, nýbrž se v rámci té jedné vyhrazené session připojení navzájem vykopávají (a tedy je to řešení, když vás server nechce pustit na RDP kvůli limitu 3 a Vám by jinak nezbývalo, než vyrazit k serveru a otevřené session sestřelit). Potřeba je pochopitelně účet s administrátorskými právy.
