Ještě než se rozpoutala kauza Benešovské nemocnice, dostalo se návštěvy ransomware i nám v HAVITu. Klasický následek – zakryptování souborů na discích za účelem získání výkupného. Poslední dobou se to docela mele, za poslední tři měsíce víme o nejméně dvou dalších případech v našem bezprostředním okolí (naši zákazníci), dalšími případy se to po internetu hemží.
Vesměs mají tyto případy jedno společné – nikde se nedočtete, jak konkrétně se ke komu škodlivý software dostal. Vše bývá zahaleno do obecné mlhy a spekulací typu „závadné přílohy mailů“ či „nezabezpečený systém“. Proto jsem se rozhodl veřejně sdílet, co víme o našem vlastním případu, jaké byly následky a jaké plyne pro nás poučení. Věřím, že to může mnohé inspirovat k vylepšení vlastního uspořádání.
Napadení první
V úterý 26. listopadu ráno jsem přišel do práce zhruba stejně s kolegou, který po usednutí a pár kliknutích zahlásil cosi ve smyslu „Sakra, já mám zašifrovanej počítač.“ Skok po síťovém kabelu už bohužel nic nezachránil – jak se během následujících chvil ukázalo, zašifrovaný byl nejenom počítač jeho, ale taky všechny on-premise servery v naší firemní síti.
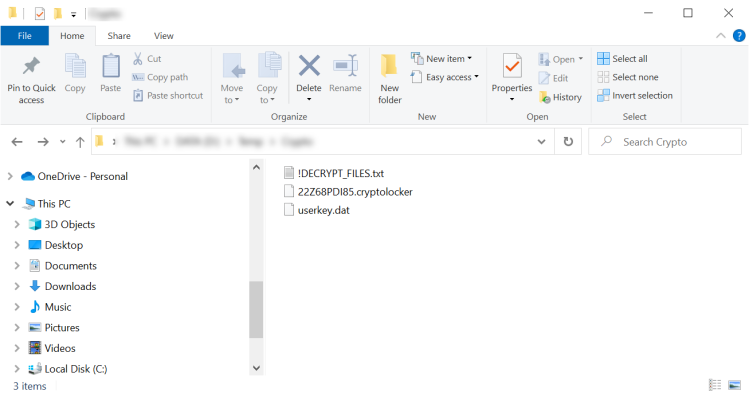
> Welcome. Please read this important instruction. Cant you find the necessary files? Is the content of your files not readable? Congratulations, you files have been encrypted. > Whats happened? Your documents, photos, databases and other important files have been encrypted with strongest encryption and unique key, generated for this computer Decrypting of your files is only possible with the private key and decrypt program The only copy of the private key, which will allow you to decrypt your files, is located on a secret server > To receive your private key follow instruction: 1) Write to our email: recovery.company@protonmail.com or rapid.file@tuta.io 2) Tell us your personal ID: KR5FLA6R1OPEI4
O co jsme přišli
Zašifrovány nakonec byly:
- všechny čtyři Hyper-V hosty, zejména všechny VHD/VHDX disky virtuálů na nich…
- file-server (obchodní dokumenty, projektové dokumenty, podklady, …)
- vývojářský SQL server (pro starší projekty s vývojem nad sdílenou DB),
- 2x Active Directory Domain Controller,
- primární on-site backup server – Microsoft Data Protection Manager (DPM),
- VPN gateway,
- legacy help-desk Kayako (přešli jsme na cloudový Jira Service Desk),
- build-agenti (ke cloudovému Azure DevOps Services – Azure Pipelines)
- stage server, kam CI build nasazuje vyvíjené aplikace pro testery,
- preview server s náhledy aplikaci pro naše klienty,
- virtuál s účetnictvím,
- pár pracovních VM pro některé scénáře vzdálené práce,
- no a ta jediná workstation kolegy, u které to začalo.
Od prvního okamžiku bylo jasné, že cestou zaplacení výkupného jít nechceme. Vytrhali jsme všechny kabely ze switchů, vypnuli WiFi, stáhli bootovací USB pro základní kontrolu a začali obcházet jednotlivé počítače i servery.
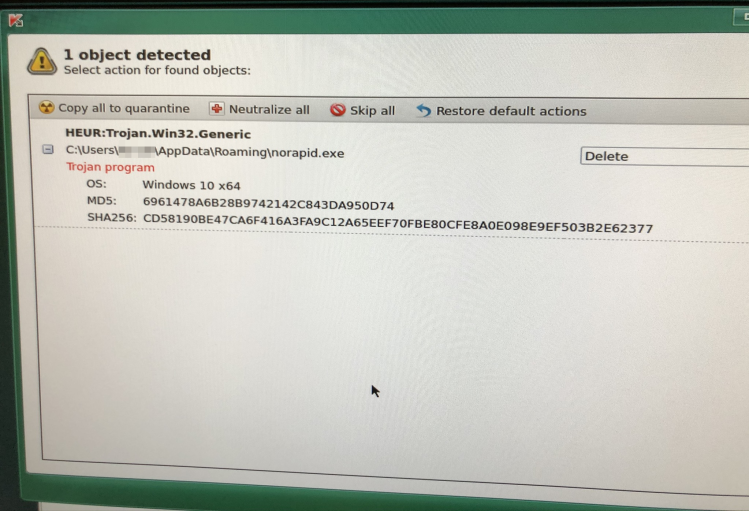
Zkontrolované počítače jsme zapojovali zpět do čisté sítě, přísně oddělenou samostatnou síť jsme si vytvořili i pro práci se špinavými servery (tu jsme nakonec ani moc nevyužili, nebylo co zachraňovat).
Co zůstalo nedotčeno
Důležitější pro nás bylo, co zůstalo nedotčeno – kromě těch pár desítek vývojářských workstation to byla zejména naše kompletní cloudová infrastruktura:
- produkční aplikace našich zákazníků v Azure,
- Office 365 ekosystém,
- Azure DevOps Services (zdrojové kódy, work-items, …)
- Atlassian Cloud – Confluence, Jira Service Desk,
- sekundární zálohy DPM v Azure Recovery Vault,
- LastPass password managers,
- atd.
Díky tomu jsme byli nakonec ochromeni jen relativně krátce a v zásadě nijak kriticky.
Obnova
Po pár hodinách počátečního chaosu a zjišťování rozsahu bylo zřejmé, že jediný možný recovery plán je kompletní rebuild celé on-premise infrastruktury od nuly, protože
- každý virtuál měl sice svoji repliku na jiném HyperV hostu, ale i ta byla zašifrována,
- Active Directory byla sice replikována na několik Domain Controllerů, ale zašifrovány byly všechny,
- do DPM jsme zálohovali jen data (soubory a databáze), nikoliv celé VHD disky či servery.
…z on-premise nezbylo opravdu nic, přišli jsme i o AD doménu bez náhrady. Naše zálohovací strategie byla primárně zaměřena na události spíše více pravděpodobné – selhání jednotlivých kusů hardware, náhodné izolované ztráty dat, atp. Co se stalo, svým rozsahem spíše připomínalo živelní katastrofu s jediným rozdílem – zbylo nám holé železo, na které jsme mohli začít stavět znovu.
Proběhla rychlá strategická porada o prioritách, o podobě nové infrastruktury, o rozdělení úkolů a pustili jsme se do toho:
- většinu souborů bývalého file-serveru jsme obnovili rovnou do Office 365 OneDrive, malý souborový server jsme si nechali jen pro rychlé lokální přenosy (Temp) a pár vývojářských sdílených souborů (rulesety pro code analyzers, atp.), kde přechod na cloud bude znamenat trochu více příprav a práce,
- protože jsme přišli o Active Directory, snažil jsem se protlačit myšlenku, že nové on-prem AD už nezaložíme a pro identity budeme dál používat už jen Azure Active Directory (+ lokální účty pro těch několik málo věcí, co nám zbudou on-prem).
- Postupem času jsem byl „přehlasován“, že on-prem AD potřebujeme alespoň na správu on-prem serverové infrastruktury samotné (např. DPM bez AD nejde nainstalovat).
- Později jsem byl „přehlasován“ i na to, že jsme do on-prem AD založili i uživatelské účty pracovníků, aby byla nějaká jednotná správa identit pro přístup k lokálním službám (a authentizaci VPN, což se nakonec nevyužije).
- Uhájil jsem zatím alespoň myšlenku „workstations nemusí být členy lokální AD, naopak se preferuje, aby byly Azure AD-joined a lokální doménové heslo si uloží jen do Windows Credential Manageru“.
- Bude to ještě boj, pár kolegů se zatím rozhodlo spojit pupeční šňůrou s novou on-prem AD (join domain) a hážou mi do toho vidle, nicméně kdo měl odvahu jít se mnou do AAD-joined režimu, myslím zatím nelituje. :-)
- Mimochodem přijít o on-prem AD prakticky znamená, že jsme všichni přišli o svůj uživatelský profil na workstation, protože ten je navázaný na doménový účet. Bez doménového controlleru sice můžou používat původní profil s cached credentials (zřejmě po neomezenou dobu), nicméně instalací nového AD do sítě (navíc se stejným názvem domény) začíná být situace veselejší – už se k původnímu profilu nepřihlásí, resp. jedině pokud se na okamžik přihlášení odpojí od sítě. Uživatelský profil lze sice přepojit/migrovat, ale výsledek je spíše nespolehlivý. Dost kolegů to využilo jako impuls k reinstalaci Windows.
- dostat zálohovaná data z lokálního DPM taky nebylo triviální, když už DPM nemáte. Je potřeba DPM nainstalovat. K instalaci DPM je potřeba Active Directory (viz výše). K lokálním zálohám dat jsme se tedy dostali až někdy v úterý pozdě večer.
- dostat zálohovaná data ze sekundární zálohy DPM v Azure Recovery Vault taky není triviální, když DPM nemáte :-). Bylo potřeba jít zdlouhavou cestou přes MARS (Azure Backup Agent), odkud se po jednotlivých položkách (DBs a volumes) data vytahovala. Je to pomalé, nepřehledné, peklo. K vytažení nejdůležitějších dat jsme se tedy dostali taky až někdy večer, upload do cílového O365 OneDrive trval postupně dalších několik dní.
- např. VM s účetnictvím jsme nainstalovali rovnou jako Azure VM (mimochodem naše úplně první VM v Azure, jinak jedeme plné PaaS)
V zásadě nám trvalo postupně zhruba týden než jsme se dostali na víceméně plnou původní funkčnost, pár detailů ladíme dodnes (např. změna VPN z Microsoft RRAS na IKEv2 přímo přes router, atp.)
Shrnutí první události
I přesto, že jsme měli a máme nejdůležitější služby v cloudu, byli jsme první dva dny dost zásadně paralyzovaní (první den jsme odhadem jeli na 5% výkonu a řešili jen kritické požadavky zákazníků, druhý den možná na 30%, pak už se to nějak rozběhlo).
Přestože jsme měli od drtivé většiny věcí datové zálohy a přišli jsme v podstatě jen o opomenutý starý help-desk, jednalo se svým rozsahem o událost, která byla pro nás zcela mimořádná a srovnatelná s živelní katastrofou. V zásadě se ukázalo, jak obrovskou výhodou pro nás je strategie postupného cloudovatění našeho fungování. O kolik hůře bychom na tom byli, kdybychom zároveň přišli o kdysi u nás běžící Exchange a TFS, to si raději ani nepředstavuji.
Způsob nakažení
No a jak se to k nám dostalo? Jistotu nemáme, protože jsme v tom zmatku napadený počítač smazali a na hlubší analýzu nedošlo. Myslíme si nicméně, že příčinou byla kombinace chybějících aktualizací Windows (kolega měl plný systémový disk a aktualizace se mu tak neinstalovaly) a publikovaného rozhraní RDP na veřejnou IP adresu (přímý port mapping na routeru).
Smůlou pak už bylo, že zrovna kolega zároveň občas pracuje se servery jako Domain Admin (intranet RDP), byť jinak pracuje pod neadministrátorským účtem.
Jiné běžné příčiny jsme vyloučili – žádný závadný soubor neotevřel, žádný nakažený soubor se nikde nenašel, uživatelské účty měly unikátní a netriviální hesla.
Napadení druhé
…neštěstí nechodí nikdy samo. :-)
Viselo to tak nějak ve vzduchu, po internetu se množily zprávy, kdo zrovna podlehl ransomware, už jsme věděli, že nikdo není neprůstřelný, jistota o způsobu první nákazy nebyla.
Jeden krásný podvečer 5.12. mi volá kolega: „Je to tu zas! XY má zakryptovaný počítač.“ (jiný kolega).
Cvičení se opakuje. Sprint k síťovému kabelu nakaženého PC, odpojení všech od sítě, kontrola všech strojů antivirem z bootovacího USB.
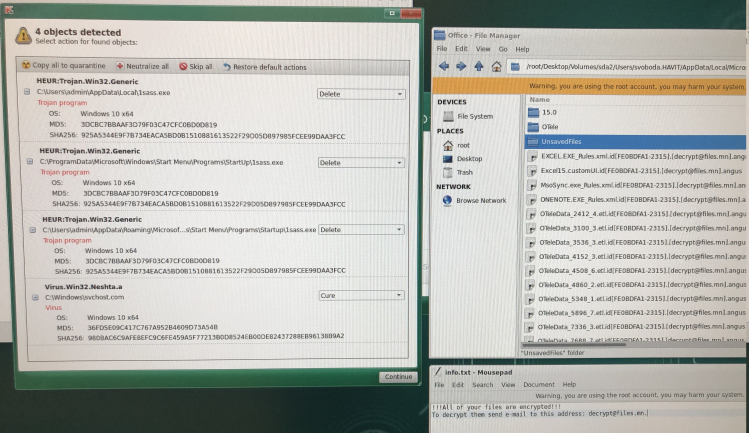
Zkrátím to – zašifrovaný byl jediný počítač (jiným ransomware, byť taky šifrující) a příčina se ukázala celkem rychle. V zápalu boje, jak jsme přišli o VPN a trvá nám připravit novou, tak jsme podlehli potřebám pár dalších kolegů a namapovali jsme jim pro vzdálený přístup RDP přímo na veřejnou IP adresu. Bylo otázkou hodin, nikoliv dnů, než došlo k průstřelu skrze zapomenutý lokální účet jednoho z nich – admin s heslem admin.
K žádnému rozšíření na další počítače nedošlo, stačilo přeinstalovat jedno PC.
V podstatě jsem za tento druhý případ rád, protože poměrně levně pomohl zviditelnit velmi slabé místo naší ochrany – RDP, resp. obecně chybu cokoliv vypublikovat do veřejné sítě, co není „pod kontrolou“.
Ponaučení
Kdo mě zná, ví, že nejsem příznivce antivirů. Sám mám na svém počítači zakázaný i Windows Defender a opírám se v této oblasti o tři jiné pilíře:
- příčetné chování uživatelů,
- řádné aktualizace,
- zálohování.
Na první dva nelze plně spoléhat, klíčový pro přežití je zejména ten třetí – zálohování.
V našem případě se potvrdilo, že antivirus by zřejmě nic nevyřešil. První kolega měl aktivní Defender (byť možná se starší databází), ale z event-logu bylo vidět, jak si s ním ransomware obratně poradil a shodil ho (stejně obratně sundal i běžící VMs z HyperV hostů a zašifroval VHDX soubory).
Zálohování
A zálohování? Zachránilo nás, byť o trochu kostrbatěji než bych si ideálně představoval. Pár věcí uniklo naší pozornosti při definování zálohovacích scénářů a způsob obnovy byl díky zániku řídícího DPM zdlouhavý.
Skončili jsme naštěstí ve stavu, kdy jsme měli dvě použitelné zálohy:
- obě s relativně hlubokou historií,
- jednu v lokálním DPM (zakryptován byl jen systém, nikoliv data na dedikovaných DPM volumes), druhou off-site v Azure Recovery Vault,
- nicméně obojí jsou to zálohy „stejného charakteru“, vznikají společným procesem, Azure Recovery Vault je v podstatě jen sekundární kopií záloh v DPM, a pokud by na celém zálohovacím procesu něco dlouhodobě hnilo, nejspíš by to postihlo obě zálohy.
Neměli jsme zálohu on-prem Active Directory. Mou strategií je eliminace/minimalizace závislosti na on-prem AD, nicméně nové AD vzniklo a zálohujeme ho nyní jako „celý VM“.
Pro zkrácení doby zotavení jsme přidali nejenom zálohování celých VHDX, ale pro některé klíčové servery zálohujeme i do Azure v režimu Recovery Services (tj. celý VM k rychlému rozjetí přímo z Azure). Obecně však prostě cloudovatíme a on-prem servery držíme jen pracovní s režimem „dvě HyperV repliky + v případě ztráty reinstall“ (no a holt když se to sejde všechno najednou, tak ten rebuild trvá).
Čerstvě jsme přidali další nezávislé zálohování na Synology NAS. Bude to taková naše off-site černá skříňka s konektivitou pouze „zevnitř ven“, u mě doma na fyzicky odděleném segmentu sítě.
- Pomocí Synology Active Backup for Office365 už zálohujeme celý náš O365 tenant.
- Skriptem budeme stahovat denně všechny GIT repositories z Azure DevOps Services, z GitHubu a podobných.
- Pomocí Synology Active Backup for Business chceme zálohovat on-prem infrastrukturu z kanceláří.
- Stahovat sem chceme i zálohy storage+DBs z produkčních aplikací v Azure.
- Zálohujeme na NAS i těch pár našich souborů z Google Drive.
(Přestavěl jsem nedávno domácí síť na Ubiquity UniFi a musím říct, že co je Ubiquity na síťařinu, to je Synology v NAS. Jsou to fakt pěkné ekosystémy.)
Ochrana
Cenné školení bojem se nám dostalo i v oblasti ochrany. Celá firma jsme v podstatě IT profesionálové, příčetného uživatelského chování, ale pořád jen lidi – chybující.
Pár věcí, které jsme po popsaných událostech změnili:
- Zrušili a zakázali jsme veškerou přímou publikaci RDP či jiných služeb z lokálních počítačů na vnější rozhraní. Jediná přípustná cesta je VPN.
- Azure Active Directory jsme přepnuli do režimu Enable Security defaults, což mimo jiné znamená, že všichni mají vynucené vícefaktorové ověřování (MFA), dosud jsme měli aktivní policy jen pro administrátory.
- Na LastPass password-manageru jsme taktéž všem vynutili MFA, dosud jen administrátoři.
- Revidujeme a vylepšujeme zálohování (viz výše).
- Prohlubujeme naši strategii využívání cloudových služeb. Jsem přesvědčený, že velcí cloudoví provideři mají mnohem (o mnoho řádů) lepší dovednosti a vybavení pro zabezpečení, dostupnost, …prostě se nám lépe postarají o infrastrukturu, než bychom to zvládli sami. Naopak sobě uvolňujeme ruce a můžeme se věnovat tomu, co umíme – vývoji aplikací (cloudových 😍).
…no a samozřejmě vycházíme z toho všeho posilněni. Vyzkoušeli jsme si disaster recovery, objevili slabá místa, dostali přes prsty, získali nové zkušenosti.
FAQ (postupně doplňováno)
- Zálohy jsme měli z předchozího dne (+ starší dle retention policy).
- HyperV hosts byly členy lokální domény.
- Přístup na publikované RDP nebyl filtrován na whitelistované IP adresy.
- Je nás cca 25 a naše strategie přežití podobných nákaz je pro on-premise založena hlavně na schopnosti rychlého zotavení (při zachování přiměřené míry ochrany, tj. snižování pravděpodobnosti problému a minimalizaci škod). Pro firmu naší velikosti a možností platí, že není otázkou jestli, ale jen kdy se něco takového stane (a podle mě to platí i pro většinu firem o řád až dva větší).
- admin/admin byl v druhém případě lokální (nedoménový) účet pracovní stanice, který měl na počítači kolega z doby několik let nazpět. Účet si tehdy vytvořil při instalaci Windows na těch pár minut, než přidal počítač do domény. No a pak na něj prostě zapomněl. Tedy kupodivu si na něj vzpomněl, poté co si nechal namapovat RDP, ale než stihl zareagovat, bylo pozdě. Nové verze Windows, pokud si dobře uvědomuji, tak toto již řeší mnohem lépe, nechají vás už při instalaci připojit do domény, nebo Azure AD, nebo k Microsoft Accountu a žádný takovýto meziúčet tam není potřeba.
